预测性见解(PI) -预测模型评估

模型评估是一种操作,用户可以通过它来估计Predictive Insights (PI)预测模型的预期性能并评估其有效性。由于预测和账户优先级可以在您的销售计划或其他业务计划中发挥重要作用,因此模型评估是关键,应该被视为建模过程的一个组成部分。
在本文中,我们将描述三种关键的PI模型评估技术。
模型质量图

模型质量图表描述了模型对数据的泛化程度,即它准确预测新(看不见的)账户的转换结果的能力。以下部分描述了图表的不同组成部分:
- X轴:显示数据集中所有帐户的覆盖范围,包括客户和潜在客户,按分数从左到右降序排序。因此,例如,0.15分代表得分最高的15%的账户,1.0分代表所有账户。请注意,A和B等级分数范围以颜色突出显示。
- Y轴:显示召回率,或所有账户覆盖率的每个值在数据集中的客户百分比(X轴)。因此,例如,0.7分代表数据集中所有可用客户的70%,1.0分代表所有客户。
- 模型线橙色显示。表示分数覆盖的每个百分比的模型召回率(真阳性率)。评分范围为0 ~ 1。
- 测试线:红色部分。表示测试集的召回。测试集是PI自动从原始数据中保留的随机数据样本,以便在训练后估计模型的质量。只有当训练集中有足够数量的帐户(超过140个唯一帐户)时,才会分配测试集。
用技术术语来说,图表将召回率表示为数据集中账户覆盖率的函数。
用户可以通过查看模型质量图来评估他们的预测模型,并考虑以下几点:
- 一般来说,较高的准确度值表明该模型在预测潜在客户的转换结果方面更有效。
- 随着覆盖率百分比的增加,模型的召回率应该有一个相对陡峭的增长,并且在覆盖率的顶端保持一个高的召回分数。
- 考虑从原点(坐标轴相交的地方)到图形右上角的对角线。如果模型的性能低于对角线,则意味着模型的性能比随机机会更差,并且很可能需要进一步细化或针对用例采取不同的方法。但是,如果模型的性能高于对角线,则意味着模型的性能优于随机机会,并且能够从数据中收集有用的信息。
- 理想情况下,模型在训练数据和测试数据上的表现应该几乎没有差异,表明模型既不是过拟合也不是欠拟合。这将表现为两条线在整个覆盖范围内重叠或紧挨在一起。
由于每个业务用例和数据集都是唯一的,因此没有关于实际精度值应该是多少的确切规范;在某些情况下,该模型将更容易识别不同的属性,从而更有效地区分客户和潜在客户——这将转化为更强的性能和更高的准确性。在其他情况下,高和低精度值可能分别表示过拟合和欠拟合行为。
分数和排名分布
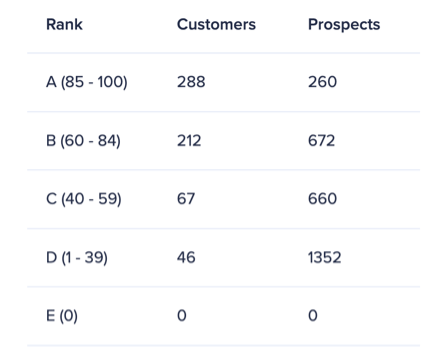
在这种评估技术中,我们检查预测模型的“帐户优先级”选项卡中可用的详细信息。我们通常希望看到一个帐户分布,其中最高级别(A)的客户数量最大,其中级别越低-客户数量越少。前景的趋势应该是相反的,低排名(D)的前景数量最大,排名越高前景数量越少。
请注意,出于这种技术的目的,E等级应该被忽略,因为它代表无法得分的帐户。同样,这种技术也适用于默认的分数阈值,其中A等级定义为85 - 100,B为60 - 84,C为40 - 59,D为1 - 39。
预测分数抽样
预测分数抽样是一种“健全检查”技术,用户通过评估预测分数的有效性来评估模型。为了执行此检查,用户应执行以下步骤:
- 从PI导出评分的潜在客户数据。
- 按分数对数据进行排序。
- 从得分最高的账户(90-100)中随机抽取5-10个账户,从得分较低的账户(1-10)中随机抽取5-10个账户。
- 考虑这些账目与你的业务目标是否相符,并检查它们是否得到了合理的评分。
有了有效的预测模型,我们期望强拟合账户和低拟合账户分别获得高和低的预测分数。指导原则是寻找逻辑上的契合,但不是所有账户的完美契合,因为模型本质上是统计性的。
注意,此技术适用于用户熟悉与模型相关的底层用例和业务目标的情况。
总之,我们建议在使用PI构建的每个模型中遵循所有三种评估技术。请注意,与任何预测模型一样,确保使用满足需求并且适合所讨论的用例。